The Quirks of Index Maintenance in Open Source Databases
인덱스 관리는 데이터베이스를 운영하는 누구에게나 정말 까다로운 과제일 수 있으며, 이를 더욱 어렵게 만드는 것은 오픈 소스 데이터베이스마다 인덱스를 다루는 방식이 다르다는 점입니다. 이번 글에서는 이러한 차이점들이 실제로 어떻게 나타나는지, 그리고 그것이 여러분에게 어떤 의미가 있는지를 자세히 살펴보겠습니다.
테이블에 row 가 추가되거나(INSERT), 수정되거나(UPDATE), 삭제되면(DELETE), 데이터베이스는 인덱스를 조정해야 합니다. 이는 컴퓨터 시대 이전의 도서관 운영 방식과 유사합니다. 예를 들어 저자, 제목, 주제와 같은 여러 인덱스를 작은 서랍들로 가득 찬 캐비닛 속 종이 카드로 관리하던 시절을 떠올려 보세요. 책이 추가되면(삽입), 누군가는 모든 인덱스에서 관련 카드를 꺼내 새로운 항목을 적은 뒤 다시 제자리에 넣어야 했습니다. 데이터베이스도 비슷한 작업을 수행합니다. 카드를 꺼내는 작업은 읽기 I/O 가 되고, 제자리에 다시 넣는 작업은 쓰기 I/O 에 해당합니다. 캐싱이 없는 경우, 각 인덱스는 최소한 한 번의 읽기와 한 번의 쓰기 작업이 필요합니다.
모든 secondary indexe 에 즉시 insert 하는 대신, 하루 일과가 끝날 때 처리해야 할 보류중인 목록(pending list)을 만들 수 있습니다. 이렇게 하면 이름이 비슷한 이름을 가진 작가의 책이나 동일한 주제의 책들이 여러 권 들어오게 되면 이 업데이트들을 병합하여 캐비닛을 뒤지는 데 드는 시간을 줄일 수 있다는 점입니다. 그러나 명백한 단점도 있습니다. 일반적인 검색을 수행할 때, 찾고 있는 항목이 최신 상태인지 확인하기 위해 “보류 중” 목록도 함께 확인해야 한다는 점입니다. 이것이 바로 MySQL InnoDB 의 Change Buffer(CB)가 사용하는 인덱스 관리 방식입니다.
이제 소개는 여기까지 하고, 6개의 큰 secondary indexe 를 가진 상태에서 1천만 개의 row 를 insert 할 때 필요한 IOPs 수를 살펴보겠습니다. 테스트 테이블의 스키마(MySQL/InnoDB 문법 기준)는 다음과 같습니다:
|
|
컬럼 a, b, c 는 무작위 UUID 값(v4)입니다. 제가 예전에 쓴 블로그 글 “MySQL UUIDs – Bad For Performance(https://www.percona.com/blog/uuids-are-popular-but-bad-for-performance-lets-discuss/)”에서 말했듯이, 저는 데이터베이스에서 특히 인덱스가 걸린 UUID 값을 그다지 선호하지 않습니다. 그러나 이번처럼 비효율적인 동작을 극대화하려는 목적이라면 UUID 는 아주 훌륭한 도구입니다. 설정과 테스트 절차에 대한 모든 세부사항은 여기에 나와 있습니다.
테스트 환경은 메모리 4GB, vCPU 2개가 할당된 KVM 가상 머신입니다. I/O 측면을 강조하기 위해 일부러 메모리를 제한했습니다. 현재 논의와 큰 관련은 없지만, 데이터 저장소는 최대 16kB 크기의 I/O 를 초당 1,000회로 제한하도록 설정되어 있습니다. 이 I/O 제한은 AWS 가 EBS 볼륨을 제한하는 방식과 비슷하며, 병목 지점을 명확히 하고 통제하기 위해 설정한 것입니다. 이번 글의 목적이 데이터 구조 유지의 I/O 효율성을 강조하는 것이기 때문에, 내구성(durability)은 다소 완화된 상태입니다.
이번 실험에서는 최신이지만 보급률이 낮은 버전이 아닌, 널리 사용되는 일반적인 오픈 소스 데이터베이스 버전들을 선택했습니다. 다음은 사용된 버전입니다:
- Percona Server for MySQL 8.0.40-31
- Percona Server for PostgreSQL 15.10
- Percona Server for MongoDB 6.0.20
Insertion results
2천만 개의 row 를 insert 하는 데 필요한 읽기 및 쓰기 IOPs 수치는 다음과 같습니다.
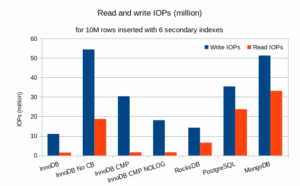
레이블은 다음 섹션에서 설명되므로, 이제 사용된 총 IOPs 수를 기준으로 결과를 자세히 살펴보겠습니다.
MySQL InnoDB
총 IOPs 관점에서 가장 효율적인 기술은 Change Buffer 가 활성화된 InnoDB 입니다. 솔직히 말해서 성능이 좋을 거라고는 예상했지만, 이 정도일 줄은 몰랐습니다. 특히 Change Buffer 를 비활성화한 경우(InnoDB No CB)와 비교하면 그 영향은 매우 큽니다. 이번 벤치마크에서 Change Buffer 를 활성화하면 write IOPs 수는 5배, read IOPs 수는 10배까지 줄었습니다! Change Buffer 가 없으면 InnoDB 의 인덱스 관리 성능은 특히 write IOP 수에서 매우 낮습니다. 이는 반드시 기억해야 할 사항이며, MySQL 8.4.x 에서는 Change Buffer 가 기본적으로 비활성화되어 있다는 점에서 더욱 중요합니다.
물론 이렇게 낮은 IOPs 수치를 얻기 위해 대가를 치러야 합니다. insert 작업이 끝난 후 인덱스들은 ” degraded(저하된)” 상태이며, B-tree 상에 누락된 항목들이 존재합니다. InnoDB 는 백그라운드에서 인덱스를 업데이트하지만, 서버 부하에 따라 이 작업은 수 시간까지 걸릴 수 있습니다. 모든 secondary indexe 를 즉시 스캔하도록 강제했을 때 약 33분이 걸렸고, 추가로 약 140만 건의 write IOPs 가 발생했습니다. 이후의 스캔은 약 7분밖에 걸리지 않았고, 추가적인 write 는 발생하지 않았습니다. 또한 Change Buffer 는 상당히 복잡하고 민감한 소프트웨어 구성요소로, 수년간 여러 문제를 겪어왔으며, 이것이 아마도 MySQL 8.4.x에서 Change Buffer 를 기본적으로 비활성화한 주된 이유일 것입니다.
MySQL MyRocks/RocksDB
이번 작은 실험에서 두 번째로 효율적인 기술은 RocksDB 를 사용하는 MySQL(MyRocks engine)입니다. InnoDB가 B+Tree 기반인 반면, MyRocks 는 내부 데이터 구조로 LSM 트리(Log-Structured Merge Tree)를 사용합니다. LSM 트리 기반 저장 엔진은 write 작업에 매우 적합하지만, insert 가 무작위 순서로 수행될 때 이렇게까지 좋은 성능을 보일 것이라고는 예상하지 못했습니다. write IOPs 약 28% 정도만 더 많았지만, read IOPs 는 4배 이상 많았습니다. 이 read IOPs 는 모두 압축(compaction) 작업에서 발생한 것입니다.
MySQL InnoDB compression
순진하게도 InnoDB 압축(CMP)을 사용하면 기록되는 데이터 양이 줄어들 것이라 생각했지만, 실제로는 그렇지 않았습니다. 데이터 파일에 대한 write 는 줄어들었지만, double write buffer 와 redo log file 에 대한 쓰기는 크게 증가했습니다. 그 원인 중 일부는 innodb_log_compressed_page 변수 때문입니다. 이 변수는 zlib 이 업그레이드될 때 압축된 페이지가 손상되는 것을 방지하기 위해, 다시 압축된 페이지를 redo log 에 기록하게 합니다. 이로 인해 redo log 는 일종의 triple write buffer 처럼 동작하게 됩니다. MySQL 업그레이드를 계획하지 않고 InnoDB 압축을 사용하는 경우, 이 변수를 OFF 로 설정하는 것을 고려할 수 있습니다. 이 기능을 비활성화한 상태(NOLOG)에서는 write IOPs 수가 거의 절반으로 줄어듭니다. 그럼에도 불구하고, 이는 원래 InnoDB 수치보다 60% 이상 증가한 수치입니다.
PostgreSQL
PostgreSQL 은 인덱스 관리에 속임수를 쓰지 않습니다. 모든 insert 작업마다 인덱스를 즉시 업데이트하며, 그 결과는 매우 우수합니다. Change Buffer 가 없는 InnoDB(NO CB)보다 훨씬 뛰어난 성능을 보였습니다. 이러한 낮은 write IOPs 수치를 달성하기 위해 checkpoint_timeout 을 30분으로, max_wal_size 를 12GB 로 설정해야 했습니다. PostgreSQL 은 WAL(Write-Ahead Logging)을 단순한 redo log 로만 사용하는 것이 아니라 일종의 double write buffer 로도 사용합니다. 이 때문에 MySQL 환경에서 PostgreSQL 로 전환할 경우, max_wal_size 는 innodb_redo_log_capacity 보다 훨씬 큰 값으로 설정해야 합니다.
MongoDB
마지막으로 MongoDB/WiredTiger 는 가장 낮은 순위를 기록했지만, 이는 튜닝에 많은 시간을 들이지 않았기 때문에 참고용 입니다. write IOPs 수만 놓고 보면, 여전히 Change Buffer 가 없는 InnoDB(NO CB)보다는 약간 더 나은 성능을 보였습니다. 이는 InnoDB 가 Change Buffer 없이 동작할 때 최적화가 되어 있지 않다는 인상을 줍니다. read IOPs 가 왜 이렇게 높은지, 심지어 MySQL 의 어떤 결과보다도 높은지 의문이 들었습니다. MongoDB 는 read 작업을 위해 file cache 에 부분적으로 의존합니다. 이는 두 개의 캐싱 시스템이 서로 겹쳐서 쌓여 동일한 데이터를 캐싱하고 있을 가능성이 높으므로 비효율적으로 보입니다.
Insert rate stability
이번 글의 초점은 인덱스 관리에 초점을 맞추었지만, insert 작업 속도의 안정성도 살펴보지 않을 수 없었습니다. 데이터베이스 성능의 안정성은 매우 중요한데, 갑작스러운 성능 저하는 전체 인프라의 안정성에 큰 부담을 줄 수 있기 때문입니다.
MySQL/InnoDB 5.0 시대에는 write 부하가 높은 상황에서 성능 안정성이 매우 낮았습니다. 이는 잦은 checkpoint 알고리즘 때문이었고, 이로 인해 빈번한 flush sync 이벤트가 발생했습니다. InnoDB 5.1 에서 도입된 adaptive flushing 기능은 이 문제를 해결하는 데 큰 진전이었습니다. 현재는, 적어도 일정한 write 부하에서는 InnoDB 가 비교적 안정적인 write 성능을 제공합니다.
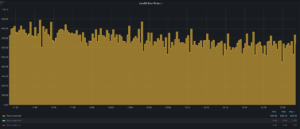
약간의 작은 변동은 있었지만, 큰 문제는 없었습니다. 이는 상당히 인상적인 결과입니다. 더 자세히 알고 싶다면, 몇 년 전 제 동료 Francisco 와 제가 InnoDB flushing 이 어떻게 작동하는지에 대해 쓴 글을 참고하시면 됩니다. (https://www.percona.com/blog/innodb-flushing-in-action-for-percona-server-for-mysql/)
IOPs 가 제한된 테스트 환경에서는 RocksDB 와 같은 LSM 기반 스토리지 엔진이 안정적인 성능을 유지하는 데 어려움을 겪을 수 있습니다. WAL 에만 write 가 이루어지는 빠른 insert 구간이 있는가 하면, write buffer 가 flush 되거나 compaction(압축)이 트리거될 때 느려지는 구간도 존재합니다. 아래에 제시된 RocksDB 결과를 보면 실제로 성능이 크게 변동하는 것을 확인할 수 있습니다.
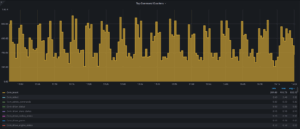
위의 결과들은 스토리지 엔진의 설계 관점에서 예상된 것이지만, PostgreSQL에 대한 초기 결과는 실망스러웠습니다. 해당 결과는 아래와 같습니다:
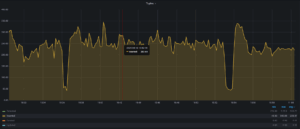
insert 속도는 대부분 안정적이었지만, 20~40초 동안 지속되는 긴 성능 저하 구간이 있었습니다. 이러한 불안정성은 한동안 저를 당황하게 만들었습니다. 만약 이 문제가 일반적이었다면 PostgreSQL 을 사용자들에게 큰 영향을 미쳤을 것이지만, 현실은 그렇지 않기 때문입니다. 다행히도 PostgreSQL 전문가인 제 동료 Jorge Torralba 덕분에 원인을 밝혀낼 수 있었습니다.
2025-06-04 00:54:35.212 UTC [] [4075872]: [1-1] user=,db=,host= LOG: automatic analyze of table "dbbench.public.data_uuid"avg read rate: 3.595 MB/s, avg write rate: 0.421 MB/sbuffer usage: 1216 hits, 29167 misses, 3415 dirtiedsystem usage: CPU: user: 1.65 s, system: 3.87 s, elapsed: 63.39 s |
기본적으로 PostgreSQL 은 전체 튜플 중 약 10%가 수정되면 statistics refresh(통계 갱신)을 트리거합니다. MySQL 의 InnoDB 도 innodb_stats_auto_recalc 이 활성화되어 있을 때(기본값) 비슷한 동작을 합니다. 하지만 두 시스템의 차이는 통계 수집에 사용하는 샘플 크기에서 나타납니다. 위 로그 메시지를 제대로 해석한 것이 맞다면, PostgreSQL 은 통계를 갱신하기 위해 3만개 이상의 block 에 접근했으며, 이는 B-tree 당 4천개 이상에 접근했습니다. 반면 InnoDB 는 기본적으로 B-tree 당 20개의 16KB 페이지를 스캔하며, B-tree 레벨 수에 따라 약 100개 block 에 접근하는 것을 의미합니다. 어쩌면 이것이 InnoDB 통계가 그토록 형편없는 이유 중 하나일 수도 있습니다. 어쨌든, 다음 명령어로 자동 통계 새로고침을 비활성화한 후:
alter table data_uuid set (autovacuum_analyze_scale_factor=0, autovacuum_analyze_threshold=11000000);
|
훨씬 개선된 동작을 얻을 수 있었습니다:
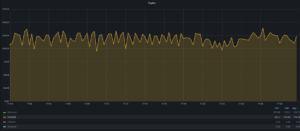
이러한 동작은 매우 예측 가능합니다. 만약 autovaccum analyze 테이블 프로세스로 인해 유사한 성능 저하를 겪고 있다면, 자동 통계 갱신 기능을 비활성화하는 것을 고려해 볼 수 있습니다. 하지만 통계가 빠르게 나빠질 수 있으므로, 야간이나 시스템 부하가 적을 때 통계를 갱신하도록 cron 작업을 설정해야 합니다.
Conclusion
데이터베이스 엔진은 수년간의 개발과 설계 선택의 결과물이며, 이 글에서 보았듯이 인덱스 유지보수와 같은 아주 간단한 작업에서도 그 동작 방식은 상당히 다릅니다. 이 insert 실험을 통해 IO 가 제한된 환경에서 얻은 몇 가지 내용을 요약하면 다음과 같습니다:
- InnoDB 의 Change Buffer 는 매우 효율적이지만, IO debt(부채)를 발생시킵니다.
- Change Buffer 없이 InnoDB 는 write 성능이 가장 나쁩니다.
- InnoDB 압축 기능은 write IOPs 를 증가시킵니다.
- MyRocks 는 I/O 관점에서 매우 효율적이지만, insert 속도 변동이 큽니다.
- PostgreSQL 은 secondary indexes 를 모두 갱신함에도 불구하고 꽤 효율적입니다.
- MongoDB 는 최하위지만, 이는 최적화 되지 않은 구성으로 나온 결과입니다.
- PostgreSQL 의 통계 수집은 결코 가볍지 않으며, IO 가 제한된 환경에서는 큰 영향을 줍니다.
- 기본 InnoDB 통계 수집은 PostgreSQL 에 비해 너무 약하며, 이는 InnoDB 가 큰 테이블에서 불안정한 실행 계획으로 어려움을 겪는 이유 중 하나입니다.
이렇게 간단한 실험에서 얻은 지식의 양에 매우 놀랐으며, 다른 시나리오들을 테스트하고 또 무엇을 배울 수 있는지 알아보려고 합니다.
자유롭게 댓글을 달아주세요! 언제나 환영합니다.
기타 문의: info@neoclova.co.kr
네오클로바 기술블로그 홈 바로가기: https://neoclova.net
네오클로바 홈페이지: http://neoclova.co.kr